


ICDM Tutorial
-- Recent and Emerging Trends in Tabular Data Generation
In the last few years, Deep Learning based models such as Generative Adversarial Network (GAN), Variational Auto-Encoders (VAE), etc. have achieved remarkable success in generating high-quality synthetic data. However, much of the success is achieved and demonstrated for structured data only such as images, text, speech, etc. - prompting a surge in research to study the efficacy of these recent trends on non-structured data such as ‘Tabular data’. Note, tabular datasets plays a pivotal role in data mining research, and capability to model a high-dimensional distribution that can generate the observed data has been investigated for quiet some time in data mining. This tutorial undertakes some recent and emerging trends for tabular data generation. Note, tabular data is a combination of apparently unrelated columns of types numeric, rank, and categorical features which makes the direct application of GAN-based deep learning methods quite challenging.
In this tutorial, we will start by discussing a simple taxonomy of tabular data generation methods to provide a brief history as well as an overview of recent and emerging techniques. In doing so, we will highlight the challenges of tabular data generation as well. In the second phase of the tutorial, we will discuss the need for standard evaluation. We will discuss various metrics that must be used when comparing competing tabular data generation models. In the last phase, we will discuss the applications of tabular data generation with a discussion of its applications in privacy-preserving analytics, robustness analysis (concept drift analysis, adversarial attacks analysis) and anomaly detection.
1. Tutorial Session (on 30th Nov 2022)
Session 1: Background and Preliminaries
- Introduction
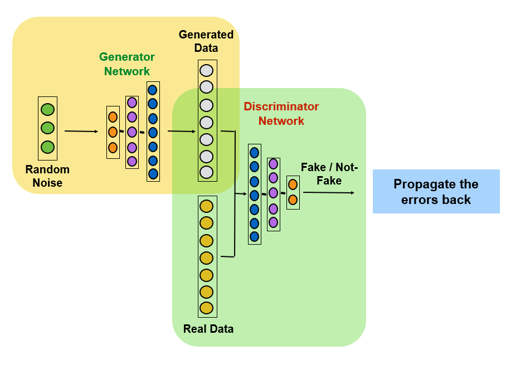
- Discussion of Generative and Discriminative Models
- Generative Models Taxonomy
- Structured vs. Non-structured Data
- Implicit vs Explicit Models
- Introduction to GAN models and adversarial learning
- Characteristics of tabular data and comparison to structured data
- Notations and symbols used
Session 2: Recent and Emerging Trends in Tabular Data Generation
- Old Trends
- NADE and its variants
- Variational Auto-Encoders and its variants
- Review of commonly used GAN-based tabular data generation methods
- GANBLR and its variants
Session 3: Lab Session
- Running state-of-the-art data generation models
- Comparing and bench-marking the results
Session 4: The Evaluation Methods on Synthetic data and Interpretation
- Introducing the train synthetic test real method
- The similarity check between the synthetic data and real data
- Interpreting the data generation process
- Live Demo for testing and comparing various methods
- Introducing platform for results sharing and comparison
Session 5: Applications
- Addressing data scarcity issues
- Data insights exploration
- Data sanitization for privacy preserving
- Differential privacy on data generation
- Robustness of learning algorithms to concept drift and adversarial attacks
- Anomaly detection
- Multi-Modality Data Generation

2. Tutorial Handout and Code
The slides for Tutorial is available here
The python library for Tutorial is available here in Tulip-lab open code , A demonstration video for using the library is available here
3. Tutorial Presenters
Dr. Nayyar Zaidi
Yishuo Zhang
A/Prof. Gang Li
Biographical Sketch of the Presenters
Dr. Nayyar Zaidi

Dr. Zaidi is currently a Senior Lecturer at Deakin University. He received the B.S. degree in computer science and engineering from the University of Engineering and Technology, Lahore, Pakistan, in 2005, and the Ph.D. degree in Artificial Intelligence from Monash University, Melbourne, VIC, Australia, in 2011. He worked as a Research Fellow, a Lecturer, and a Research Fellow, from 2011 to 2013, from 2013 to 2014, and from 2014 to 2017, respectively, at the Faculty of Information Technology, Monash University. From 2017 to 2019, he worked as Research Scientist at Credit AI (Trusting Social) Melbourne Lab. His research interests include effective feature engineering, explainable model, uncertainty prediction, and reinforcement learning. He is also interested in practical data science, machine learning engineering, and data science training. He was a recipient of the Gold Medal for graduating top of the class at the University of Engineering and Technology.
Yishuo Zhang

Yishuo Zhang received his B.S. degree in computer science from the University of Zhengzhou, China in 2010, and the M.S degree in information technology from Monash University, Melbourne, VIC, Australia, in 2013. He currently is the second year Ph.D. student at the School of Information Technology, Deakin University and his research interests include big data feature engineering, tabular data generation, the trust-able and explainable model and tourism demand forecasting.
A/Prof. Gang Li

A/Prof Gang Li, IEEE senior member, received his Ph.D. in computer science in 2005. He joined the School of Information Technology at Deakin University (Australia)as an associate lecturer (2004-2006), lecturer (2007-2011), senior lecturer (2012-2016). His research interests are in the area of data mining, machine learning, and business intelligence. He serves on the IEEE Data Mining and Big Data Analytics Technical Committee (2017-2018 Vice Chair), and IEEE Enterprise Information Systems Technical Committee, IEEE Enterprise Architecture and Engineering Technical Committee, and serves as chair for IEEE Task force on Educational Data Mining (2020-2023 Chair). He acts as an associate editor for Decision Support Systems (Elsevier), IEEE Access (IEEE), Journal of Travel Research (Sage), and Information Discovery & Delivery (Emerald), and Human-Centric Computing and Information Sciences (Springer) etc. He has been the guest editor for IEEE Access, the Chinese Journal of Computer, Journal of Networks, Future Generation Computer Systems (Elsevier), Concurrency and Computation: Practice and Experience (Wiley) and Enterprise Information Systems (Taylor & Francis). He has co-authored 8 papers that won best paper prizes, including KSEM 2018 Best Paper award, IFITT Journal Paper of the Year (2017, 1st prize), IEEE Trustcom 2016 best student paper award, Journal Paper of the Year (2015, 3rd award) from IFITT, the PAKDD2014 best student paper award, ACM/IEEE ASONAM2012 best paper award, the 2007 Nightingale Prize by Springer journal Medical and Biological Engineering and Computing. He has also conducted research projects on tourism and hospitality management. He served on the Program Committee for over 150 international conferences in artificial intelligence, data mining, machine learning, tourism and hospitality management, and is a regular reviewer for International Journals in the areas of data science, privacy protection, recommendation system, and business intelligence.
Acknowledgements
Jiahui Zhou. Final year Master student in Xi'an Shiyou university, her research interests are in big data feature engineering, adversarial data defense

Haiyang Xia. Second year PHD student in Australian National University, his research interests are in tourism competitiveness analysis, casual inference, and the big data feature engineering.
